
Golang中协程实战之——工作池(控制并发)
前置说明
今天实战讲解golang中的协程的用法,假如有一个需求:在有限的协程数量范围内,尽可能的并发处理任务达到最大利用资源的目的。
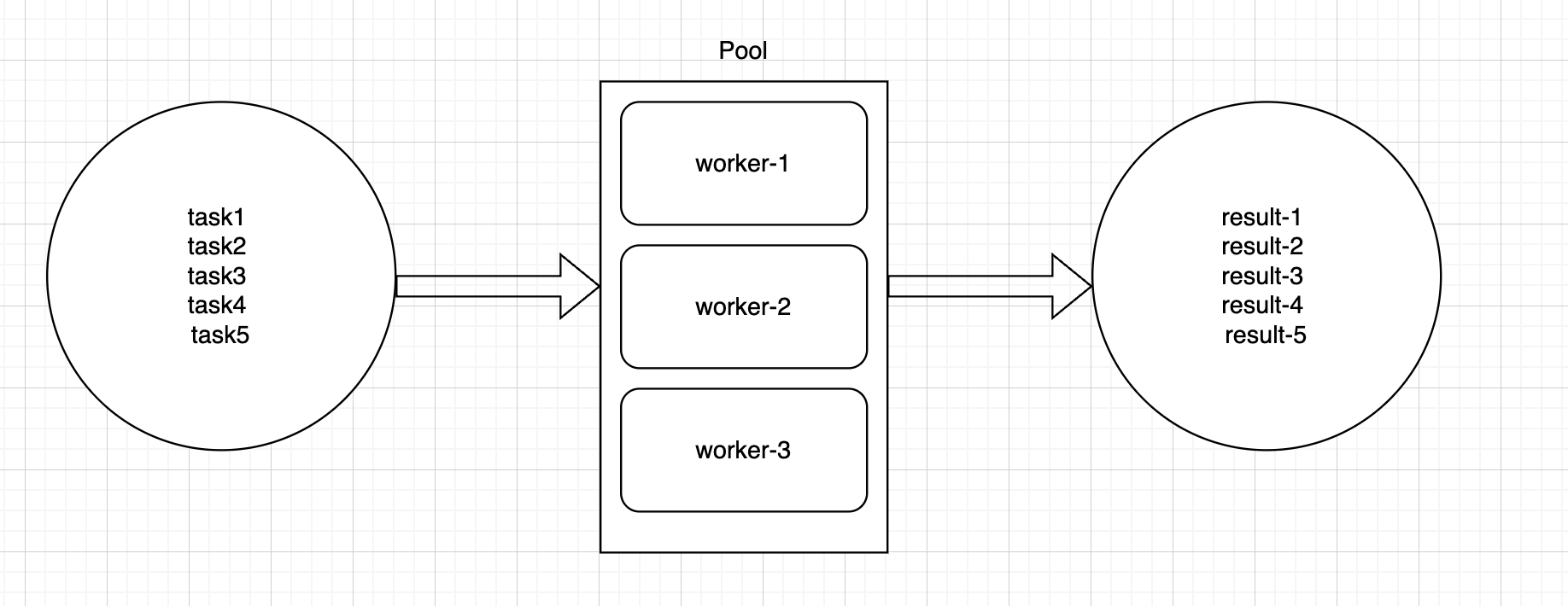
上图是一个简易的任务流程图,首先我们发布了5任务 task-1 task-2 task-3 task-4 task-5,而我们的Pool池子就只有3个工作协程,最终要输出5个结果 result-1 resukt-2 resukt-3 resukt-4 resukt-5。
如果在资源够用的情况下,那么直接起5个协程跑任务完全没问题,但是在实际生产中我们无法控制任务的输入的数量,这里举例是5个任务,但实际可能是100个甚至1000个或者更多,那么如果直接按照任务数量来创建协程,最后带来的结果很大可能是内存和CPU暴涨甚至崩溃。
因此我们要限制协程数量的基础上最大并发达到资源最优利用,就需要用到协程池。
实施步骤
协程池需要做几个事情:
- 根据数量入参创建对应的协程。
- 每个协程执行一件任务,执行完毕返回结果,然后再从任务中获取。
- 当所有的任务都完成以后返回结果集
开始我们的代码:
-
按照上述的步骤,我们首先定义任务和协程池,由于只是常规例子就只定义了
workNum。type Target struct { Name string } type Pool struct { workerNum int } -
然后定义任务和结果:
type Task struct { target Target idx int } type Result struct { target Target Success bool FailedMsg string Latency time.Duration } -
创建协程池:
func NewPool(workerNum int) *Pool { return &Pool{workerNum: workerNum} } -
协程池创建完毕就是执行任务方法,该方法入参是ctx上下文和targets,targets列表就是要执行的任务列表。
根据targets的数量创建一个results用于返回对应数量的结果。然后创建一个
taskChan协程,协程的buffer数量则是任务targets的长度,这样就是非阻塞的通道,创建完毕以后将任务放入taskChan通道内,填满通道等待后续的任务执行,这里需要close(taskChan)是因为后续的任务执行遍历通道以后可以正常退出,如果不关闭通道则会一直处于等待中。然后创建一个
WaitGroup用来计数和等待所有任务完毕。最后就是核心的工作池的流程,这里使用for循环遍历工作池的数量,目的就是限制工作池。每个工作开启一个协程来执行任务,执行完毕以后将任务结果装填到
results结果集内。最后
wg.Wait()等待所有任务都完成以后返回results结果集。func (p *Pool) RunTask(ctx context.Context, targets []Target) []Result { results := make([]Result, len(targets)) taskChan := make(chan Task, len(targets)) for i, target := range targets { taskChan <- Task{target: target, idx: i} } close(taskChan) var wg sync.WaitGroup wg.Add(p.workerNum) for range p.workerNum { go func() { defer wg.Done() for task := range taskChan { if ctx.Err() != nil { results[task.idx] = Result{ target: task.target, Success: false, FailedMsg: ctx.Err().Error(), } continue } log.Printf("task %d: begin\n", task.idx) results[task.idx] = p.do(ctx, task.target) log.Printf("task %d: done\n", task.idx) } }() } wg.Wait() return results -
单个任务执行方法,这里随机了5秒内的时间来模拟不同任务的执行效率。并且计算出任务执行耗时。
func (p *Pool) do(ctx context.Context, target Target) Result { result := Result{target: target} select { case <-ctx.Done(): result.Success = false result.FailedMsg = ctx.Err().Error() break default: begin := time.Now() time.Sleep(time.Duration(rand.Intn(5)) * time.Second) result.Success = true result.Latency = time.Since(begin) break } return result } -
至此工作池就完成了,接下来就是测试代码,首先模拟了5个任务,然后
NewPool(3)创建一个3个工作协程的池子。最后执行完任务以后打印结果:func TestWorkPool(t *testing.T) { targets := []Target{ {Name: "test1"}, {Name: "test2"}, {Name: "test3"}, {Name: "test4"}, {Name: "test5"}, } ctx, cancel := context.WithTimeout(context.Background(), 10*time.Second) defer cancel() begin := time.Now() p := NewPool(3) results := p.RunTask(ctx, targets) t.Logf("all task took %v", time.Since(begin)) for _, result := range results { t.Logf("result: %+v", result) } } -
以下是执行
test的打印,从结果集的打印来来耗时总时间是超过3秒的。而我们最后任务打印的总执行耗时是2秒。所以达到了并发效率,同时也限制了资源的使用。➜ pool go test -v . === RUN TestWorkPool 2026/03/31 22:22:31 task 0: begin 2026/03/31 22:22:31 task 1: begin 2026/03/31 22:22:31 task 0: done 2026/03/31 22:22:31 task 3: begin 2026/03/31 22:22:31 task 3: done 2026/03/31 22:22:31 task 4: begin 2026/03/31 22:22:31 task 2: begin 2026/03/31 22:22:31 task 2: done 2026/03/31 22:22:32 task 4: done 2026/03/31 22:22:33 task 1: done work_pool_test.go:23: all task took 2.001740291s work_pool_test.go:25: result: {target:{Name:test1} Success:true FailedMsg: Latency:22.667µs} work_pool_test.go:25: result: {target:{Name:test2} Success:true FailedMsg: Latency:2.001386791s} work_pool_test.go:25: result: {target:{Name:test3} Success:true FailedMsg: Latency:167ns} work_pool_test.go:25: result: {target:{Name:test4} Success:true FailedMsg: Latency:84ns} work_pool_test.go:25: result: {target:{Name:test5} Success:true FailedMsg: Latency:1.000670541s} --- PASS: TestWorkPool (2.00s)
总结
上述协程池只是一个简单的工作模式,在实际生产中还会存在很多的逻辑,例如任务不可能仅仅只是一个名字,并且上述代码并没有实际触发 ctx的超时,这里添加超时上下文是需要控制任务时间,毕竟不可能让任务无限制的执行下去,对资源也是一种消耗。
最后协程用法千千万万,这里只是一种而已,也是比较简单的一种,适合在限制资源内定时执行特定的任务。这里其实跟 errgroup比较像。